QUESTION 1
According to the TensorFlow website (https://www.tensorflow.org/hub/overview), TensorFlow Hub is a “repository and library for reusable machine learning. The tfhub.dev repository provides many pre-trained models: text embeddings, image classification models, and more.” Basically, its a library like sklearn that has many useful tools related to machine learning. We used TensorFlow Hub to import the IMBD datasets which contains the movie reviews training and testing sets and the embedding model that “maps a sentence into its embedding vector” (https://www.tensorflow.org/tutorials/keras/text_classification).
QUESTION 2
The optimizer is how the model “learns” and the loss function tells the optimizer how to improve. The loss function makes a certain computation (can be based on many different functions, for example “BinaryCrossentropy” or “Mean Squared Error” that tells the optimizer how far away it is from the correct answer. The optimizer then optimizes based on the loss function and once again tests the model. This then happens over the epochs, each time the model calculating the loss and the optimizer optimizing the model. The model had an accuracy of .9519 and a loss of .1465 after 30 epochs for the training data. The model had an accuracy of .863 and a loss of .3063 for the testing data. The model is definitely overfit.
QUESTION 3
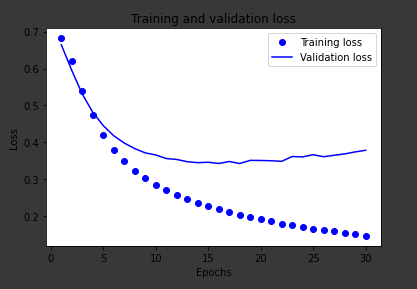
In this graph, training loss is the loss computed by the loss function. Validation loss is another component that is calculated by the loss function but not used to update the weights unlike the actual loss. It is a measure of how far off you were from the correct answer at the current epoch.
In this graph, there is an increasing difference between training and validation loss starting at around 5 epochs. However, the model continues to minimize the loss of the training data yet the validation loss seems to increase after a while.
QUESTION 4
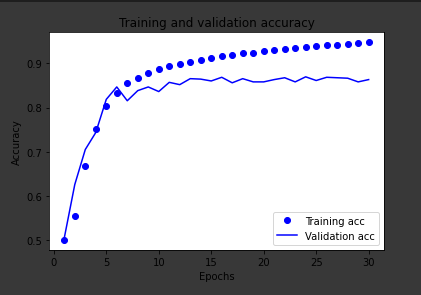
In this graph, the graph is between training and validation accuracy. The graph seems to plateau at around 10 epochs, and the increasing difference between the training and validation accuracy indicates overfitting as the model is memorizing the noise of the data and not the generalizations of the data that you could use to predict on future data.