QUESTION C
- “This approach is inefficient. A one-hot encoded vector is sparse (meaning, most indices are zero). Imagine we have 10,000 words in the vocabulary. To one-hot encode each word, we would create a vector where 99.99% of the elements are zero.”
Source: https://www.tensorflow.org/tutorials/text/word_embeddings
Word embeddings are used to create associations between words like in the sarcasm detector. The model can assign values to words (1 being the highest and 0 being the lowest) based on their association to certain features. For example, Andrew Ng poses the problem man:woman :: king:?. The model can solve this problem by taking word embeddings of the features (gender, royal, age, food) in relation to the word, thereby creating a vector specific to each word which can then be used to solve the analogy.
Source: https://www.youtube.com/watch?v=EEk6OiOOT2c.
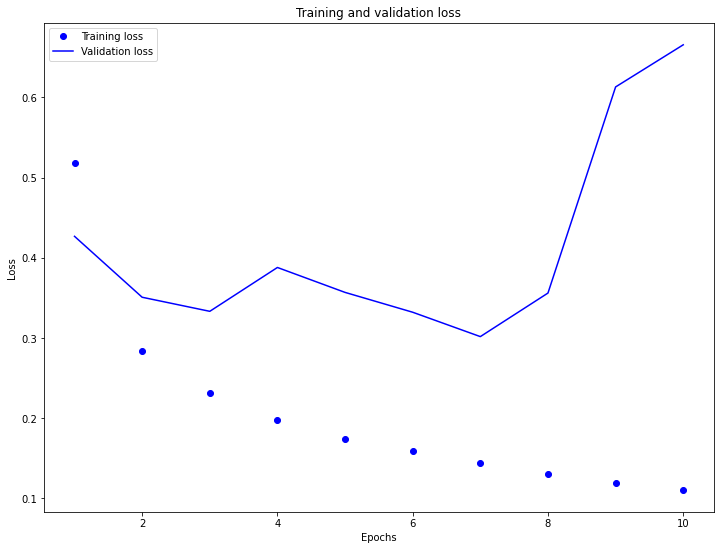
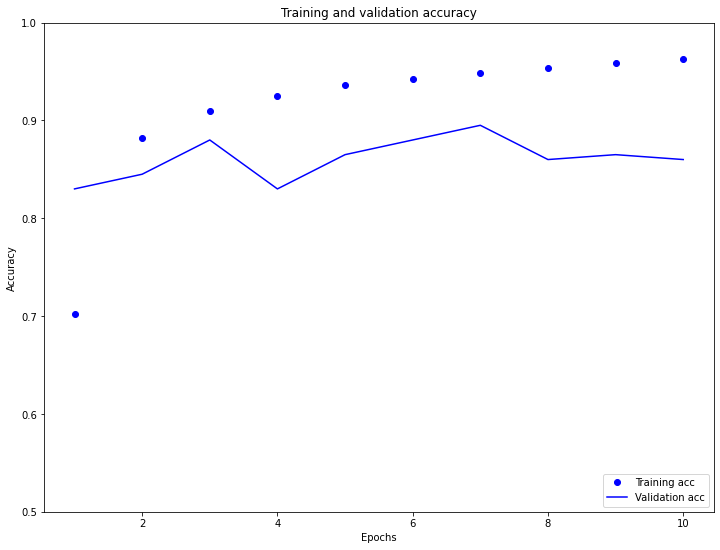
- The training MSE kept on decreasing over the 10 trained epochs. However, the test MSE actually increased at around 3 epochs and kept on increasing over the 10 trained epochs. In comparison to the training and validation accuracy, they both increased but the testing accuracy stopped around 86%. Both trends indicate the the model is overfitting to the training data.
QUESTION D
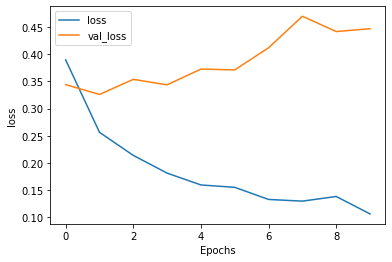
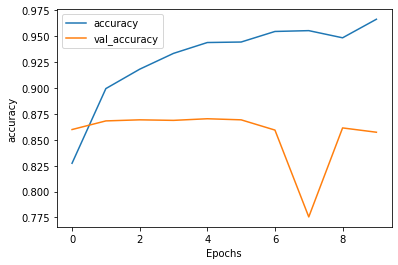
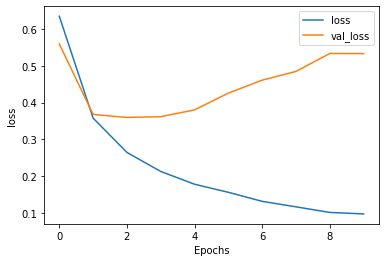
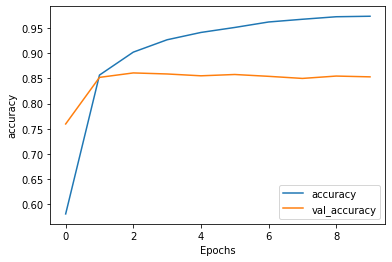
- As expected, over 10 epochs, the training loss for both the single and double layer LSTM layer model decreased. The validation loss for both the single and double layer also started to increase at epoch 1. Interestingly, the validation loss in the double layer LSTM model was higher compared to the single layer LSTM model (loss 0.5335 vs 0.4466). For the training and loss and accuracy, both increased smoothly over the 10 epochs as expected to around 97%. Both the validation accuracies plateaued around 85%. However, for the single layer LSTM model, there was a large dip at epoch 7 where the validation accuracy dipped below 80%. This is different compared to the double LSTM model that plateaued at epoch 1.