QUESTION A
-
It seems that the labels were split from the training set by the .pop method. The name of the labels dataset is train_y.
-
Some estimators from tf.estimator include BaselineClassifier, BoostedTreesClassifier, DNNClassifier, DNNLinearCombinedClassifier, LinearClassifier.
The script follows this pattern: tf.estimator.Estimator(model_fn, model_dir=None, config=None, params=None, warm_start_from=None) -
“Input functions supply data for training, evaluating and prediction. Feature columns describe how the model should use the input data from the features dictionary.”
Source: https://www.tensorflow.org/tutorials/estimator/premade -
The command .train() takes in training data input_fn and trains a model based on input_fn. The argument hooks can be used for “callbacks inside the training loop.” The argument steps are the “number of steps for which to train the model.” The argument max_steps is the “total steps for which to train the model.” The DNNClassifier classifier was used. The DNNClassifier was given the feature columns for its feature_columns argument, defined with hidden_units=[30,10] (two layers, separated by comma, with 30 and 10 nodes respectively), and defined with n_classes=3 for the 3 classes (Setosa, Versicolor and Virginica). As I understand it, the input_fn requires a tuple as an input with (features, labels). The input_fn is set as lambda to “capture the arguments while providing an input function that takes no arguments, as expected by the Estimator.” I believe the nested function is this: input_fn=lambda: input_fn(train, train_y, training=True), where you send a row one at a time to train the model using the data and the classification and feeding it to the input_fn argument.
Source: https://www.tensorflow.org/api_docs/python/tf/estimator/DNNClassifier -
For the DNNClassifier, the test set accuracy was 0.800 and: Prediction is “Setosa” (59.4%), expected “Setosa”,
Prediction is “Virginica” (51.4%), expected “Versicolor”,
Prediction is “Virginica” (71.5%), expected “Virginica.”
For the DNNLinearCombinedClassifier, the test set accuracy was 0.733 and:
Prediction is “Setosa” (77.4%), expected “Setosa”,
Prediction is “Virginica” (45.9%), expected “Versicolor”,
Prediction is “Virginica” (63.0%), expected “Virginica.”
For the LinearClassifier, the test set accuracy was 0.967 and: Prediction is “Setosa” (99.2%), expected “Setosa” Prediction is “Versicolor” (97.2%), expected “Versicolor” Prediction is “Virginica” (96.1%), expected “Virginica”
For this iris data set, ranking in terms of performance is: LinearClassifier, DNNClassifier and then DNNLinearCombinedClassifier.
QUESTION B
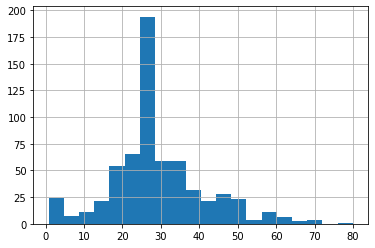
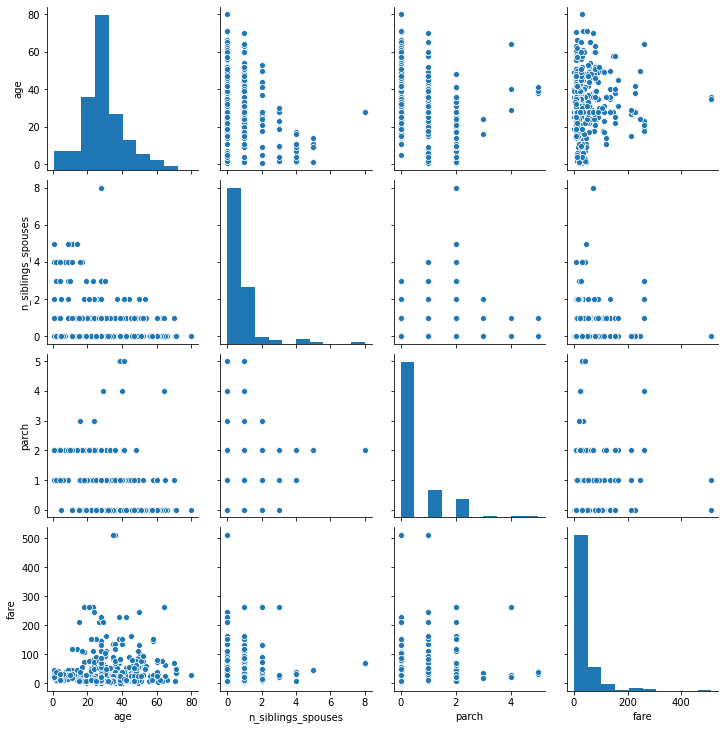
-
The two plots look about the same, the reason that they are not the same is because of the axis label interval is larger, so there is less detail. Since this pairplot does not include the non-numerical data like gender, it is impossible to generalize on this data. However, based on the data presented, I believe that there is no correlation between these variables.
-
A categorical column refers to a column that takes all the categories (variables) that is put inside a list. A DenseFeature seems to be a column that holds the particular data that goes with a categorical column. It fills empty spaces with zeroes to mark the locations where data exists or doesn’t exist.
-
The feature columns that were put inside the LinearClassifier include sex, n_siblings_spouses, parch, class, deck, embark_town, alone, age and fare. I would say that the results of the inital output were pretty bad. A 75% accuracy is pretty bad for a trained model, especially once it starts predicting. The cross featured columns are used to combine certain features if the model is doing poorly on evaluating a problem based on singular features alone. Yes, incorporating a cross feature column between age and gener improved model performance by a little bit (about 2%).
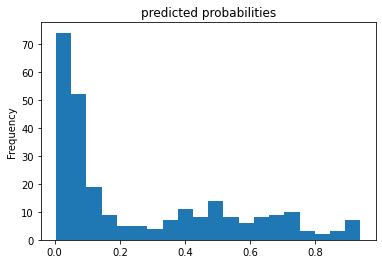
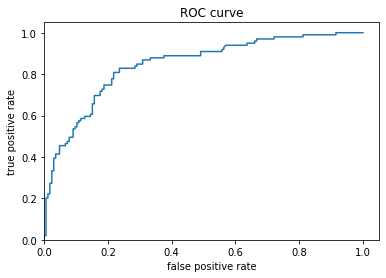
Based off of the ROC curve it seems that the model was pretty good at predicting whether the person died or survived. It is not perfect but it is by no means bad. The predicted probabilites show that the model predicted that about 70% would die and no one was guaranteed to survive. Overall, the model is okay.