QUESTION A
My topic is a recurrent neural network that recommends (predict) anime based on an input watchlist based on what the user has watched. I believe that only recently have companies started to personalize their ads. I would instead like to apply this to anime, or Japanese animation. Much like how Netflix recommends shows based on what you have watched, I want to do the same but with anime. The problems that I believe that I will encounter will be getting an entire database of anime (MAL or Anilist), designing the neural network, and text processing. I like to imagine dystopian scenarios and sometimes even dream of them. For some reason, I have always been fascinated with how the world might look in a few hundred years. This type of recurrent neural network will be so important because how efficient it could be in eliminating the need to browse, saving time. Imagine not having to go out to shop but having a robot delivering an outfit to your home that you know will be about 100% accurate to your tastes. In the future, as this technology becomes more advanced, it could very well just take the entire human population and predict a person’s aptitude for a certain job. I will design this recurrent neural network to take in a list of anime watched. Inside the recurrent neural network, I hope to load in a database from MAL or Anilist and have the network take the current genre (Drama, Romance, Comedy, etc.) and classify a probability that you watch a certain genre. After that, the network will search for anime that you might like based on these genres. If possible, I would like to have the computer take note of the user’s ratings: a rating of 1 should probably not be included in a user’s probability to watch it. Also, on the flip side, the network should not recommend something that the community has decided is bad (probably below 6). The network generalizes this and then maybe outputs 5 recommendations to the user. I believe that this will be a large scale project, as I have no idea how to build a recurrent neural network. However, I believe that what I will learn in this class will give me a good idea. The part that will take the longest time is designing the neural network to work the way I want. This is a very complicated network with 3 or so restrictions to accomplish. Not only that, but it will also connect to a website and download information from it and analyze it.
QUESTION D
-
The cats and dogs lab uses the RMSprop optimizer. According to the reading, it seems that RMSprop was created in response to a problem in Rprop. Rprop is a response to stochastic gradient descent’s problem where it is impossible to have a global learning rate due to the many minimums that SGD is trying to minimize towards each time, giving it is randomness. Rprop attempts to solve this problem by “only using the sign of the gradient with the idea of adapting the step size individually for each weight” (Bushaev). But it seems that Rprop doesnt work with large datasets that require mini-batch weight updates, since it violates the idea behind SGD similar to how derivatives work. By taking a curve and fitting rectanges to match the curve’s shape, we can calculate roughly the curve’s area by summing the rectangles together. “When we have small enough learning rate, it averages the gradients over successive mini-batches.” However, in Rprop we only use the sign of the gradient and meaning that it is not guaranteed that we would have an average that evens out over successive mini-batches. Instead, RMSprop forces the gradient to be about the same for all adjacent mini-batches so that they average out thus perserving the idea of SGD. This is apparently done by using the root mean square. It seems that Adagrad is different in its implementation but similar in how its applied. Adagrad takes a “historical sum of squares in each dimension” and adapts the learning rate by dividing the running sum by the learning rate. As you keep dividing, the steps become smaller and smaller hence the diminishing learning rates in Adagrad. So what RMSprop does instead to combat the diminishing returns is instead of keeping a running sum it keeps a running average.
Source: https://towardsdatascience.com/understanding-rmsprop-faster-neural-network-learning-62e116fcf29a -
The cats and dogs lab uses the binary cross-entropy loss function. This function takes that data and fits a Logistic Regression to the data. Then it takes the predicted probabilities for all the points based on whether yes, they are (1.0 prob) or no, they are not (0.0 prob). Then, by taking the negative log of the probabilites computed we will get a large loss for wrong predictions and a small loss for right predictions. By taking the mean of all the losses, the number represents the overall loss.
Source: https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a -
The metric argument is used to track certain data while running the compile function such as MeanSquaredError or Accuracy. In the cats and dogs lab we use the metric argument in order to track our accuracy. This metric is stored in a History object which is returned by the method .fit().
-
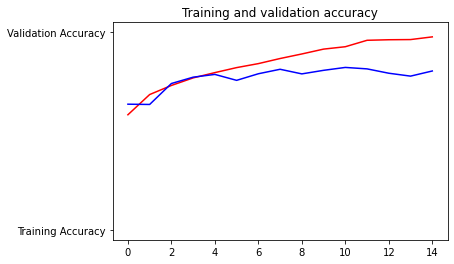
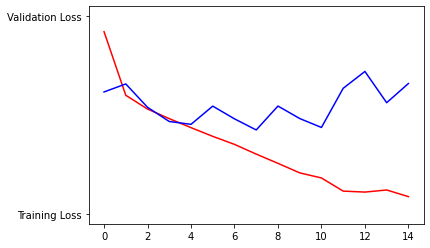
Both the training and the testing accuracy increase over the 15 training epochs. However, the testing accuracy starts to plateau over around 7 epochs at. The training loss kept on decreasing, however, testing loss started fluctuating around 4 epochs and eventually started increasing at around 10, meaning that the model is becoming overfit. Considering that the model reached about 82% testing accuracy and 97% training accuracy, I would say the model is a little overfit but an okay model. -
Cat1: Cat1 is a dog.
Cat2: Cat2 is a cat.
Cat3: Cat3 is a dog.
Dog1: Dog1 is a dog.
Dog2: Dog2 is a dog.
Dog3: Dog3 is a dog.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This model did not predict well at all. I chose Cat1 and Cat2 to be clear cats with no distracting background, only focusing on the face. Cat3 was a test to see whether the model could recognize a cat based on other features, but it seems to have failed as well. Looking back on this, it seems that the model actually somehow incorporated the background into its evaluation between cat and dog. I base this hypothesis on the fact that the program was able to determine Cat2, which had a white background vs Cat1 and Cat3 which did not have a white background. I would suggest training the model for a few less epochs since it was overfitting by 10 epochs and also train and test the model on blank backgrounds. When evaluating based on real world images, take the cat or dog and cut out the background and then predict based on that.